Amazon has finally released a big statement regarding the recent server disruptions it experienced, which led to some sites having massive losses in service, and people to question the reliability of the cloud.
When I say that the statement is “big” I mean it. I will post a few choice snippets here. First, a quick summary at the beginning:
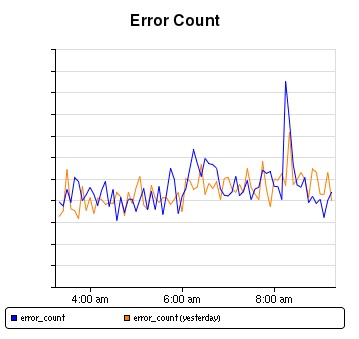
The issues affecting EC2 customers last week primarily involved a subset of the Amazon Elastic Block Store (“EBS”) volumes in a single Availability Zone within the US East Region that became unable to service read and write operations. In this document, we will refer to these as “stuck” volumes. This caused instances trying to use these affected volumes to also get “stuck” when they attempted to read or write to them. In order to restore these volumes and stabilize the EBS cluster in that Availability Zone, we disabled all control APIs (e.g. Create Volume, Attach Volume, Detach Volume, and Create Snapshot) for EBS in the affected Availability Zone for much of the duration of the event. For two periods during the first day of the issue, the degraded EBS cluster affected the EBS APIs and caused high error rates and latencies for EBS calls to these APIs across the entire US East Region. As with any complicated operational issue, this one was caused by several root causes interacting with one another and therefore gives us many opportunities to protect the service against any similar event reoccurring.
It then gets into an overview of the EBS system, and technical details of the outage and recovery, as well as the impact on the Amazon Relational Database Service (RDS). Then it talks about prevention, which is probably the most important takeaway, considering businesses rely on Amazon to stay up and running:
The trigger for this event was a network configuration change. We will audit our change process and increase the automation to prevent this mistake from happening in the future. However, we focus on building software and services to survive failures. Much of the work that will come out of this event will be to further protect the EBS service in the face of a similar failure in the future.
We will be making a number of changes to prevent a cluster from getting into a re-mirroring storm in the future. With additional excess capacity, the degraded EBS cluster would have more quickly absorbed the large number of re-mirroring requests and avoided the re-mirroring storm. We now understand the amount of capacity needed for large recovery events and will be modifying our capacity planning and alarming so that we carry the additional safety capacity that is needed for large scale failures. We have already increased our capacity buffer significantly, and expect to have the requisite new capacity in place in a few weeks. We will also modify our retry logic in the EBS server nodes to prevent a cluster from getting into a re-mirroring storm. When a large interruption occurs, our retry logic will back off more aggressively and focus on re-establishing connectivity with previous replicas rather than futilely searching for new nodes with which to re-mirror. We have begun working through these changes and are confident we can address the root cause of the re-mirroring storm by modifying this logic. Finally, we have identified the source of the race condition that led to EBS node failure. We have a fix and will be testing it and deploying it to our clusters in the next couple of weeks. These changes provide us with three separate protections against having a repeat of this event.
Then, there’s plenty more about the impact to multiple availability zones and recovery, before Amazon addresses another big element of this story, which has come under significant fire from the media: the company’s lack of communication on the whole matter (something that seems to be a trend in the tech world these days):
In addition to the technical insights and improvements that will result from this event, we also identified improvements that need to be made in our customer communications. We would like our communications to be more frequent and contain more information. We understand that during an outage, customers want to know as many details as possible about what’s going on, how long it will take to fix, and what we are doing so that it doesn’t happen again. Most of the AWS team, including the entire senior leadership team, was directly involved in helping to coordinate, troubleshoot and resolve the event. Initially, our primary focus was on thinking through how to solve the operational problems for customers rather than on identifying root causes. We felt that that focusing our efforts on a solution and not the problem was the right thing to do for our customers, and that it helped us to return the services and our customers back to health more quickly. We updated customers when we had new information that we felt confident was accurate and refrained from speculating, knowing that once we had returned the services back to health that we would quickly transition to the data collection and analysis stage that would drive this post mortem.
That said, we think we can improve in this area. We switched to more regular updates part of the way through this event and plan to continue with similar frequency of updates in the future. In addition, we are already working on how we can staff our developer support team more expansively in an event such as this, and organize to provide early and meaningful information, while still avoiding speculation.
We also can do a better job of making it easier for customers to tell if their resources have been impacted, and we are developing tools to allow you to see via the APIs if your instances are impaired.
Finally, the apology:
Last, but certainly not least, we want to apologize. We know how critical our services are to our customers’ businesses and we will do everything we can to learn from this event and use it to drive improvement across our services. As with any significant operational issue, we will spend many hours over the coming days and weeks improving our understanding of the details of the various parts of this event and determining how to make changes to improve our services and processes.
The company was good enough to give affected customers a 10-day credit (equal to 100% of usage of EBS volumes, EC2 instances and RDS database instances that were running in the affected availability zone).

 @SeanSmithSucks
@SeanSmithSucks 23 hours ago via Twittelator · powered by @socialditto
23 hours ago via Twittelator · powered by @socialditto
 @LiamRas
@LiamRas @engadget
@engadget @microfun
@microfun @phranck
@phranck @IsTheStoreDown
@IsTheStoreDown @RobLoBue
@RobLoBue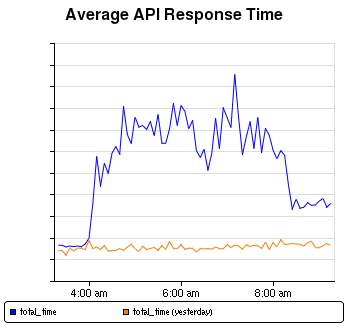











 In Hotmail, one way we monitor the health of the email service is through automated tests. We set up a number of accounts with different configurations, and then use automated tests to log into these accounts, simulate normal user activity and behavior, and report when errors are found. We use scripts to create and delete these test accounts in bulk. The way we delete a test account is to remove its record from a group of directory servers that route users and incoming mail to the correct mailbox.
In Hotmail, one way we monitor the health of the email service is through automated tests. We set up a number of accounts with different configurations, and then use automated tests to log into these accounts, simulate normal user activity and behavior, and report when errors are found. We use scripts to create and delete these test accounts in bulk. The way we delete a test account is to remove its record from a group of directory servers that route users and incoming mail to the correct mailbox.